Pandas - append
Appending to a dataframe makes a copy every time, so big performance hit when used iteratively. Using a dictionary is fastest,
It's been a long time, but I faced the same problem too. And found here a lot of interesting answers. So I was confused what method to use. In the case of adding a lot of rows to dataframe I interested in speed performance . So I tried 3 most popular methods and checked their speed.
SPEED PERFORMANCE
- Using .append ( NPE's answer )
- Using .loc ( fred's answer and FooBar's answer )
- Using dict and create DataFrame in the end ( ShikharDua's answer )
Results (in secs):
Adding 1000 rows 5000 rows 10000 rows
.append 1.04 4.84 9.56
.loc 1.16 5.59 11.50
dict 0.23 0.26 0.34
From < https://stackoverflow.com/questions/10715965/add-one-row-in-a-pandas-dataframe >
It is worth noting that concat() (and therefore append() ) makes a full copy of the data, and that constantly reusing this function can create a significant performance hit. If you need to use the operation over several datasets, use a list comprehension.
frames = [ process_your_file(f) for f in files ]
result = pd.concat(frames) From < https://pandas.pydata.org/pandas-docs/stable/merging.html >
Expressed as for loop:
csv_data = pd.DataFrame()
for csv in glob.iglob(here + '/logs/**/*.csv', recursive=True):
csv_data.append(pd.read_csv(csv,
error_bad_lines=False,
warn_bad_lines=True,
index_col=False,
ignore_index=True)) As list comprehension:
csv_data = [
pd.read_csv(csv, error_bad_lines=False, warn_bad_lines=True, index_col=False)
for csv in glob.iglob(here + '/logs/**/*.csv', recursive=True)
]
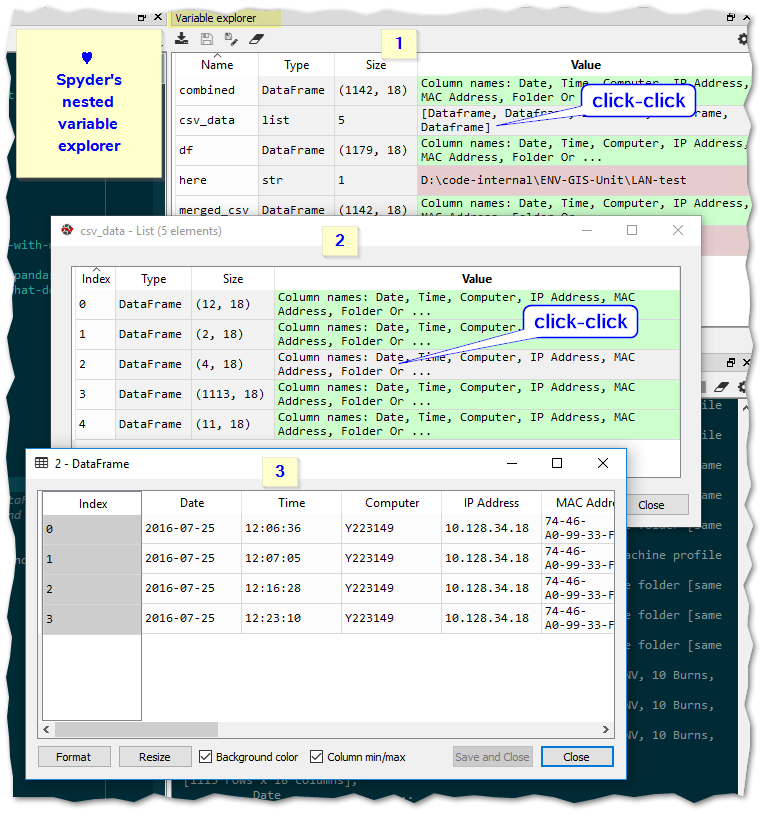
merged_csv = pd.concat(csv_data, ignore_index=True) and, the Spyder python IDE is awesome. I'm a convert. :) Winning killer feature over the many others I've used to date: interactive live variable explorer